Critical Topics: AI Images, Class EIGHT
Flowers Blooming Backward into Noise
I want to start this class on diffusion models at the beginning. Not just the beginning of diffusion models themselves. But at the beginning of actual time. I’m talking about the Big Bang. For physicists, the Big Bang is the theory that one, extremely dense point in the universe popped open. The universe expanded from that single point — and the evidence is the static on our TV sets. Buried between the images of television broadcasts is the microwave radiation unleashed by the Big Bang. We hear it on the radio, and it’s rendered on TV as static and noise, breaking down our signals.
What if you had to take all of those points of static swirling around on your TV screen and reassemble them into a single image. How would you go about piecing together all that flying radiation back into whatever dense mass was there at the start of the universe? Sounds impossible - and it is! - but how would you start?
Jump ahead 14 billion years. Diffusion models start at the same place: a frame of static. Every image produced by diffusion models like DALLE2 or Stable Diffusion or MidJourney starts with this - a random jpg of Gaussian noise. Static! Like this:


An example of a Stable Diffusion starting point.
When we ask a Diffusion model to create an image, the first thing it does is create a frame of random noise, like what we see above. (Sometimes it’s blotchy smears of color, like at the right).
It takes that noise and aims to reduce noise until it arrives at a picture. It’s doing this similar to the ways we might look up at the universe out there, in the nighttime sky, finding constellations in the random noise of stars. We see Orion’s belt, or the Big Dipper, because that’s what we have learned to see, or someone has told us it is there. But sometimes, we just see constellations and say, “that’s the Big Dipper,” because someone told us that’s what the constellation was.
Machines need to be told exactly what to find and how to find it. The machine isn’t simply asked to find a picture of flowers in the static. So, how do you train a machine to find images in noise?
Diffusion does it by starting with real images, and learning how those images break down when we strip information out of them.
Below you see flowers that might appear in some AI training data. Diffusion models are trained by watching these images decay. They start with an image and then they add noise — or remove information, which is the same thing. This noise follows what is called a Gaussian distribution pattern, clustering around certain parts of the image.
Below, each image has had progressively more information stripped out. Look at each image and note what changes. You’ll see that the image is still pretty clear for quite some time, even though it gets a noisier. What the model would do is sample those small differences, and calculate the change between one image and the next like a trail of breadcrumbs that lead back to the previous image. It will measure what changed between the clear image and the slightly noisier image. And then it will take out more info and walk that back. It will do it again, and again, and again.
























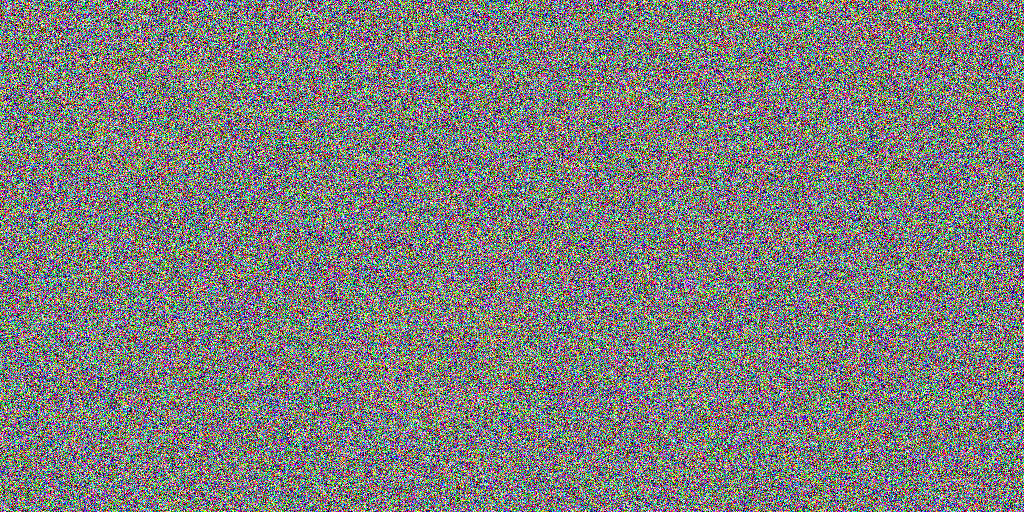



To really get a grasp on this, look somewhere in the middle of the above spread of pictures. Where does the image finally disappear into real noise? What pieces of the image remain visible the longest?
The stems maybe get lost first. We still see some key color variations. Fairly late in the process, the clusters of flower petals are still kind of visible.
So towards the end of the cycle the amount of noise can be introduced at a faster rate. At this point, you still see the very bare abstraction of those flowers. But you can still see it, because the breakdown of this image is following a pattern where the density of certain pixels is still quite strong. Gaussian noise tends to follow a pattern - a loose pattern, but one that tends to hang out around a central space. In this case, that space is the flower petals. So this is something the machine is quote unquote learning, or, in realistic terms, it is accounting for this distribution of noise and calculating a way to reverse this noise.
This image, in a few steps, disappeared completely. But the model will have learned the patterns found in the noise along the way. And when it arrives at a frame of absolute static, it will know how to work its way back to the starting point. It will know what to look for first, because those big, clumpy petals will have stayed longer in the process.
So OK, at this point the image is obliterated. And the machine has learned how that noise spread across this image. Now, key thing, this was just one image in the dataset. And it started from one specific, complete image: the source image. That source image was broken down slowly, and that breakdown was measured and remembered by the model. Now, when the model encounters a frame of static, or a random image with static, it is going to apply those rules backwards. In other words, it is going to attempt to reverse the breakdown of an image into noise. It will do this by following a path drawn from doing this with millions of images, with each image breaking down in its own way.
Another way to think of it is from its namesake: Diffusion Models are named after diffusion, the same thing that happens when a droplet of liquid enters into a larger pool of liquid. It diffuses. And while the shape of the initial droplet is unrecognizable, you could still have a sense of which direction it came from. Knowing certain rules, you might be able to trace that paint splatter backward, if not following the exact same trajectory, then at least into a rough sense of where the paint came from in the first place.
Part Two: CLIP and Language Prompting
Another important part of this is language. If you remember our conversation about GANs, you might remember that there was a kind of checks-and-balances system. The generator created random clusters of pixels, and the discriminator checked those pixels against the training data. If it was close enough, it didn’t filter out the generated image.
Diffusion models don’t work the same way, but there is still something that the model tests against. It’s actually a different model, and in Stable Diffusion and DALL-E, it’s called CLIP. CLIP is designed to describe an image. If you load an image into CLIP, CLIP will tell you lots of things that it recognizes in the image. Remember, the basis of all of this AI is really about identifying and classifying pictures. CLIP is the state of the art version of that in 2024. It’s a huge model trained on human labels, captions, and other text that surrounds images.
In the training process described above, we might have had the word “flowers” associated with that picture. As it breaks down, this word, “flower,” becomes associated with the various steps in the process. So, if we use an image of noise and say “flower,” it can look for those big, basic clusters of pixels that sort of look like petals. It’s a way of describing a picture that doesn’t exist, and telling the machine to find it.
It’s kind of image recognition run backwards. Instead of uploading an image and having a machine label it, we give the machine a label and ask it to scan the noise and recover the patterns associated with that label.

Results from the prompt “Flowers in the Nighttime Sky” from Stable Diffusion.
These prompts constrain the possible pathways that the model is allowed to take as it walks backward through the noise. When we prompt flowers, for example, the model is constrained: it can’t use what it’s learned about the breakdown of cat photographs. But, it has learned a LOT about the paths that noise takes through the breakdown of flower pictures. So you could constrain it further: Flowers in the nighttime sky. Then you have new sets of constraints: Flowers, but also night, and sky. You can set style constraints: here we have an image taken on a specific type of film format, for example, giving it a specific sense of time.
The machine will make an image, and then CLIP will analyze it. If what CLIP identifies in that image is close enough to your prompt, it will move further along in cleaning up the noise, checking in with CLIP at each step. If you prompt for “Big Dipper” and CLIP sees “New Jersey,” it will add and remove noise differently, until CLIP sees “Big Dipper.”
Your prompt becomes part of the information available to the model to make sense of the image. We give it noise, but we say: this noise is a picture of flowers at night. And then the model works to uncover the noise from this photo of flowers that doesn’t exist.
Let’s take it step by step then.
You type a prompt into the model. The model interprets your prompt as a set of words. These words - actually, combinations of letters, which may or may not be words - are associated with specific mathematical recipes for rebuilding images associated with those letters in that sequence. The model applies these to a randomly generated jpg of nothing but noise. Then it works on that noise in reverse, attempting to predict its way back to a source image, but the source image doesn’t exist. At each step, it’s reassessing what it just did, checking it against an image recognition system to see how it compares to the patterns that system has learned, and uses that as feedback to remove or add more noise.
Finally, you have an image that the machine has never seen before, but based on millions of images that it has learned to break down in a similar way. In the end it takes the output of this process, with the text embedding removed, and compares it to the same image with the text embedded, and uses this to sort of refine and polish the final product.
So this is the heart of diffusion models. But there’s one more key piece, which is, how do these diffusion models know what your prompt even means?
There are a few answers to that question, but both come down to new ways of categorizing training data.
You may remember from our talk on Generative Adversarial Networks, or GANs, that GANs were somewhat limited in that you had to train a single category of data at a time, and it was often unreliable. If you wanted to create an image of a cat you had to generate a cat from the cat dataset. And those datasets were hard to build. As OpenAI writes,
“The ImageNet dataset, one of the largest efforts in this space, required over 25,000 workers to annotate 14 million images for 22,000 object categories. In contrast, CLIP learns from text–image pairs that are already publicly available on the internet.”
In other words, you and I built this system whenever we put a picture online with a label describing it.
The idea is that the information in an image with the label “picture of a peach” was probably a peach; and if it wasn’t, it would work itself out - the vast majority of photos labeled “peach” would contain a peach. The text that these models draw from includes not just captions but also alt-text, the text behind images that are designed to be read aloud by text-to-speech systems for web users who use assistive technologies.
CLIP, which stands for Contrastive Language-Image Pre-training, is an image recognition neural net that doesn’t require categories in advance, but works was trained on human-labeled photographs from the web. It’s been designed in a way that assumes a connection between the pixel information in that image and the text used to describe that image. CLIP is a way of navigating that information, and it was applied to something called the common-crawl dataset of internet images.
OpenAI’s data is proprietary - not public - so we don’t really know what CLIP did for their dataset. But a similar open model, LAION 5B, contains about 5 billion text-image pairs in a similar frame. Once upon a time, we could go and look at it. In the video above, you can see me type “Flowers in the Nighttime Sky” and see what images in the training data were associated with those words.
Stable Diffusion is built on LAION, and so is MidJourney, though each tweaks the data for specific results based on the type of aesthetics they want to encourage in their output. What’s common across these tools is that typing a prompt constrains the diffusion model down into a narrower set of options. This is helpful to understand: every possible image is in a picture of noise. Without training data, these systems just don’t work. It goes from looking at any image at all in the noise to specific images based on your prompt, and that prompt requires CLIP to calibrate the removal of noise and refinement of the outcoming image. Those options are learned from the labels created by humans who upload photographs to the internet.
The problem with this approach is that the internet is written by humans, and not always humans at their best. And LAION has a lot of problematic representations - including stereotyping, violent, and pornographic imagery. Even when these images are censored from the final output, they nonetheless shape the collective model of images that these tools draw from.
Below are some random screen grab of LAION’s training images for the word “American.” Scroll through them. Just like we did with GANs, think about what kind of common patterns you see in these images. What’s there? What is missing? What kind of picture do you think the patterns in these images would produce?











You’ll see plenty of stereotypes at work, from Big Gulps, flags, guns, and a man tackling a deer at Wal-Mart. And these kinds of stereotypes are pervasive, because LAION is categorizing all of these images according to the internet’s description of the images. It’s not really that there are stereotypes in the dataset. It’s that the dataset is, literally, built on describing commonly associated things into the same label.
The result of all that data is below — an image created from the prompt, “American.”

What connections can you see between the images in the training data and the image it produced?
In later classes we’ll go into what the internet has to say about people and things and how the way we talk about things online shapes the output of these systems in problematic ways. But for now, I want to go back to thinking about what the model does and how we make sense of what it does: the story we tell ourselves about what this system is doing.
So now that we know how Diffusion works on a technical level, we should note the words that are often used to describe this process. Is a Diffusion model “imagining” the photo? “Dreaming” the photograph? The technology is incredible — there’s no doubt about it. But is it anything akin to the workings of a creative, human unconscious?
Part Three: Do We Understand “Understanding”?
This brings us to a classic debate in artificial intelligence. It’s inherent in the name itself: Can the tool understand what it’s doing? Is an artificial intelligence system actually intelligent? Some would argue that the way diffusion models make art is identical to how humans make art, and therefore the AI is an artist. Others challenge that concept, saying there’s a key distinction between human minds and computers.
This debate is, more or less, a repackaged debate around the Turing test, otherwise known as the imitation game. This is the idea, proposed by Alan Turing in a 1950 paper, that if a machine could write text that could pass as human, it should be considered intelligent.
A challenge to this proposal came in 1980 from philosopher John Searle in a paper called "Minds, Brains, and Programs.” Searle suggested a thought experiment. He imagined himself locked in a room with boxes of papers. On those papers are Chinese characters he couldn’t read. There’s also a dictionary: he can look for a Chinese symbol, and find out which box he should go to in order to pull out a response. Soon, a note slides under the door. It’s a letter from a native Chinese speaker. Searle takes the note and goes to the book, matches the symbol on the note to the symbol in the book. The book tells him to go pull out a response from, say, box 11. Searle goes to box 11, grabs a piece of paper, and slides it back under the door. The Chinese speaker on the other side is satisfied.
The question Searle poses is: does the occupant of the room “understand Chinese?”
There are many responses to this. One of them is the clear answer: Searle, who here represents the computer system in human form, says no, he does not speak or understand Chinese. There are other arguments, however, which suggest that, well, maybe Searle doesn’t understand Chinese, but the room understands Chinese.
That is, one might look to the room as a system, the way we look at a translation engine, and say it “understands” Chinese. The counter argument to this is that the room doesn’t actually understand Chinese, because rooms can’t understand anything. The room just realistically simulates the understanding of Chinese. But look closely, and it is simply manipulating symbols.
Another response to Searles’ argument is that it doesn’t matter if the man in the room understands Chinese. What matters is that an understanding is created between the room and the person who does understand Chinese. In other words: if the person outside the room can have a conversation with the person inside the room, then together they form a kind of understanding. But if Searle can’t understand what is being said in that conversation, then the system isn’t working.
This is an AI art class so I want to reframe the Chinese Room argument a bit. Let’s call this version of the thought experiment the Puzzle Library. Consider the art of Tim Klein.
Tim Klein is an artist who realized that jigsaw puzzles used templates: if you bought a particular brand of these puzzles in the 1980s, they all had images printed on the same set of puzzle pieces, making them interchangeable. Klein realized he could draw from these pieces and assemble them to create new images by combining pieces from different box sets. This is a good way to think about diffusion: its able to assemble many different *categories* together into the same image, which is a huge leap over the stricter categorization of GANs.

Tim Klein
We can think of a diffusion model, also, as drawing out a piece of these puzzles and assembling them by putting all of the pieces next to the first piece until it finds a match, and then restarting the process. The diffusion model doesn’t “understand” the image that it is making: it simply lays down a pixel of a certain color, based on the last color it encountered, drawing from a box of puzzle pieces from a particular set. Scramble up those pieces, and the model would make images like the one above: unaware of what it was making, aside from what came before.
Instead of being locked into a room with boxes of Chinese characters, let’s say we are locked in a room with a bunch of these puzzle pieces poured into numbered boxes. These puzzles are in fragments, scrambled up, and we don’t know what the image they make actually is. It’s just pieces scrambled up. Each of these boxes and pieces is numbered, and there’s a book that tells us which box to go to and which piece to pull out. So a note slides under the door: it’s an artist, with a prompt. You bring the prompt to the book and look up each word, and write down the corresponding number for the box and the piece. Then you go to the box and dig around for the piece, putting them onto a board as you pull them out.
In the end, the man in the room has assembled an image. But do they understand the meaning of the image they made, or the meaning of the boxes these pieces came from?
In this thought experiment, the person outside the door is the prompt writer. The person in the room is moving information from CLIP and LAION, which has assembled text and image relationships into sets of probabilities. From these probabilities come instructions for where to go to find pieces of the image that is then generated.
The version of Searle’s question we might ask is: did the person in the room make art? Or the person outside the room? You might say no, because the person did not act with the intent of making art. The person acted with the intent of finding pieces together from a set of rules.
The puzzle room metaphor may not be the best parallel. But the Chinese Room debate is an interesting and important one. Searles would say that the person inside the room is simply moving symbols from one box to the next at the instructions of a book in correspondence to the requests of the person outside. If the person inside the room can’t be said to understand Chinese, I suggest that the person inside the room shouldn’t get credit for making art, either. But what about the person outside of the room?
Another response to this paper, Cole 1991, suggests that if there is any understanding of Chinese emerging from the room, the understanding is that of the one who wrote the instructional book that Searle is following, and put together the boxes of Chinese characters. This reflects the position that in these closed-off systems, what matters is the data and the program. The data and the program don’t understand, they enact rules created by those who do. Thus, Cole writes, we could consider the room a kind of “virtual mind,” or a virtual extension of the person who writes the code. The artist, then, is the system: including the person writing the prompt.
Yet another argument comes from those who defend Neural Networks as metaphors for the human brain. Because humans can understand, and because the neural networks are modeled on human brains, the argument is that the process of translating Chinese through a neural network is much closer to human understanding than Searle is giving it credit for.
Searle addressed this, too. He proposed that the human in the room was now activating a series of pipes that were laid out according to a map of the human brain. The man in the room is then giving instructions for how much water flows through those pipes and in what sequence, mirroring the electrical activity of the human brain. The water then ultimately pools at a level that indicates the location of the proper Chinese character, or, in our case, the piece in the puzzle box. Searle writes:
the man certainly doesn't understand Chinese, and neither do the water pipes, and if we are tempted to adopt what I think is the absurd view that somehow the conjunction of man and water pipes understands, remember that in principle the man can internalize the formal structure of the water pipes and do all the "neuron firings" in his imagination. The problem with the brain simulator is that it is simulating the wrong things about the brain. As long as it simulates only the formal structure of the sequence of neuron firings at the synapses, it won't have simulated what matters about the brain, namely its causal properties, its ability to produce intentional states.
This is a key question to ask about AI: where is the intention based, and where is agency to change that intention? If an AI system is an extended, virtual mind of the algorithms and code it follows and the data it has been designed to collect, can the AI be said to have any agency, or freedom of choice, or intentionality, to the outputs it makes? Or is it more accurate to say that the person outside of the system — the user, and the designer — are the ones who have varying degrees of control over that output? So I leave you with the question of whether AI understands, or is able to produce its own meanings, or if that meaning is made by the viewers and designers of the system looking on from the outside.
Part Four: What Should We Call an AI Image?
I want to change the conversation a bit to another question, which is how we describe the products of something like DALLE2 or Stable Diffusion.
In the early days of technology, we often don’t quite know how to name things. Today we have a debate about whether AI images should be called AI images at all: some prefer image synthesis or generated images. In the early days of photography, you had similar discussions, and a quick look at the proposed names for the images that came from cameras shows you how people were grappling to make sense of that technology. Many of these names focused on the capture of light — a key aspect of camera technology, where light hit chemicals on film, and the film reacted in ways that captured the image. Before we called them photographs, we had different proposals: Photogenes, Heliographs, Photograms, Sun-prints. None of them caught on, but they tell us how people started making sense of this new technology. Photogene, for example, refers to the after-image burned onto the retina just after closing our eyes.
Today we have a debate about whether AI images should be called photography at all: some prefer image synthesis or generated images. The images made by diffusion don’t capture any light at all. They produce light: as purely digital images, they simply produce information about which pixels on your screen should be lit up. So we can’t call them photographs if we want to be true to the meaning of the word. So if these images don’t capture light, what do they capture?
Well, as we’ve seen, they capture categories. They have looked at billions of images and sorted those images according to labels. And we produce images through a prompt that activates those categories and inscribes those categories of images into an image.
This is why this class will spend so much time thinking about data, and algorithms, and how information gets assigned to categories. They reflect decisions, structures, and assumptions about the world - most fundamentally, the assumption that internet captions will appropriately describe the images that they contain. We will look at a vast body of work that looks at how algorithms have absorbed human biases, which can include deliberate and intentional choices as well as unintended ones.
This relationship of data and categories to these images can be thought of as a distinct art form, but it comes from a fairly long lineage of generative artworks. The data revolution has radically changed what these works look like, but the fundamental definition of generative art holds true.
Galanter 2003:
“Generative art refers to any art practice where the artist uses a system, such as a set of natural language rules, a computer program, a machine, or other procedural invention, which is set into motion with some degree of autonomy contributing to or resulting in a completed work of art.”
It’s said that the first generative art works were first displayed in February of 1965 by Georg Nees & Max Bense. Nees was working at a technology company, and had been writing rules for a computer to follow to draw images using simple algorithms. In the 1972 Computer Art exhibition catalog — an exhibition of computer art which took place in India — the process was described in a way that might sound familiar from the start of the lecture, where we described the production of random noise and the rules the computer followed to turn it into an image:
“Through these programmes the computer recieves a series of instructions from which it then calculates the configuration of the finished work. This can either be displayed during the process of calculation on a screening device, or the data can be first fed on to a magnetic tape or on to a punched tape, by which the output devices are then controlled.
A characteristic of many programmes for aesthetic structures is the inclusion of chance. In the structural scheme some parts remain empty so that they have to be dealt with during the process of realization. The programme does not provide a single work of art but a whole variety. For the determination of the independent variable, a so-called random-generator is employed. Here one can use a physical device, which provides random impulses - a geiger counter for example, which registers the irregular impact of radio-active particles, or a frency generator, by means of which disruptions from the atmosphere or from inside the machine are amplified by electronic conductors.”
So we can see the lineage of what we call “AI generated images” going back to algorithmically constructed images as far back as 1965. Here’s another work, by Mezei Leslie, from that 1972 exhibition, called “Transformation of a Girl’s Face,” contrasted with the output of MidJourney. Mezei Leslie’s work starts with a computer drawing and it transforms algorithmically according to the code. Arguably, that’s what MidJourney is doing on the right. The difference between the two is the vast size and complexity of datasets - which is, as we’ve mentioned, the internet — as well as the processing power we have on hand to automate the analysis of those datasets.


Chance plays a role, and so does constraint. The process is more refined, but it is not evidence of some new kind of intelligence. Instead, it’s the latest step in a march of increasing photorealism, fueled by larger amounts of data and more complex algorithms. While the aim of artists working with generativity varies, generative art is not radically new. Our capacity for detail has changed.
The degree of control we have as artists over these technologies can also vary widely. In a conversation between Christiane Paul, curator for digital media at the Whitney, and Jon Ippolito, former curator for digital art at the Guggenheim, Paul suggested a key distinction between the history of generative art and today’s generative AI art:
“[AI art] is a term you read in The New York Times, or hear in the media all the time. And what people mean by that, most of the time right now, is putting a prompt into DALL-E, Midjourney or whatever and generating an image. That’s not what we talk about when we say AI Art in the fine art world. … AI art as I would use it is art in which concepts related to AI technologies are enacted based on a practical engagement with the technologies — AI art as rooted in a critical, conceptual and structural employment of artificial intelligence.”
Debates around the definition and role of the artist have once again been renewed — and we should have those debates, because fidelity and realism in computer generated images certainly does change the conversation. It raises the specter of illustrators losing jobs, of digital artists being automated away to machines that can generate game art or illustrate children’s books. These are real concerns. But these concerns aren’t new, either. That doesn’t mean they’re unimportant. But how should artists respond to these challenges? And how can AI artists working today think of their practice as one “rooted in a critical, conceptual and structural employment of artificial intelligence?” Is this impossible with AI image making tools we have on hand today? Is it about the technology, or the artist, or some mix of both?
Back to the 1970s, John Canaday, a New York Times art critic suggested that computer artists were too concerned with the use of computers to make art in forms that already existed. He wrote that the artists in a computer exhibition were relying too much on the imitation and conventions of recognized forms of art. Rather than using computers to create paintings or drawings that a human could make, he wondered, why not emphasize things that only the computer could do? He even suggests a computer rendering of a snail in great detail, thinking about the possibilities of the single line being drawn - a line that consists of miles, if it were straight, and impossible for a human to do by hand. But he goes so far as to bemoan that the piece is named after a snail — a thing a human would recognize - instead of the algorithmic formula that drew the image.
He writes:

“Exhibitions of computer art have been popular sideshows for several years now, and about 40 examples have been assembled as part of the convention’s program, which has as its over-all goal “to interface the computer industry with the problems of society and the world.” The least of these problems, it seems to me, is to teach computers how to give us more of what artists are already giving us too much of. If the computer is going to be used as an art tool, it should be used to produce art peculiar to its peculiar nature, art which — like the pattern illustrated to the left — is literally impossible of execution by hand.”
Another artist, Robert Mueller, writes in “Idols of Computer Art” in 1978 that he is tired of a set of cliches in computer generated art — what he calls idols. The cliches are these:
"Idols of Nature,” - landscapes, flowers, plants and trees: boring
"Idols of the Formula,"- mathematical formulas used to generate shapes without human reference, often chaotic or hard to comprehend: not pleasing enough
"Idols of the Kaleidoscope," in which mathematics are used to create abstract symmetries: too pleasing
"Idols of the Game," that is, works that make use of pure randomness without any tension with order or control;
"Idols of Disguise" - taking old works and making them new through the “eye” of the computer; that is, to say: the computer can create a “version” of another famous artwork, such as a reinterpretation of Paul Klee, or can combine, for example, Jodorowsky with Tron.
"Idols of the Eye” is the use of computers in creating optical illusions.
So I want to point out that this guy was calling out computer artists in 1978 - nearly 50 years ago - for a great number of things that we do continue to see today. Art critics and curators and writers who have an understanding of this long history of generative images often echo these criticisms. If you think that AI art came about from DALLE2 and DIffusion, you’re tempted to see everything through the lens of a revolutionary technology: everything will seem new, and radical. If you look at the pieces people are generating from the long lens of art history, though, you might be a little harder to impress. The novelty isn’t there.
As practitioners, it’s crucial to find a balance between these two positions. Most of us aren’t aiming to have our Diffusion work reviewed by the New York Times. There is a long history of art in which students imitate and refine the work of those who came before. In this class I encourage you to dig into some of the histories we’re talking about and mine them for new ways to play with the tools you have, setting aside any desire to make something radical or revolutionary. I’d rather you hold on to any excitement for the potential of these tools, and use them to try things out in new and playful ways.
Because the argument about what’s new in art is also something of a cliche. But there’s a long history there, too, and I hope we can eventually have questions around the role of human artists in these datasets, and the complex question of appropriation. But for now, I encourage you to lean in to any excitement you have for these tools, and explore them with a sense of curiosity, but to think through the lens of how to make something that feels like your own.
Aside from what kind of images you want to make, there are questions of how you want to use the images themselves. Are they simply there to be looked at? Or are they the starting point for something else? This question brings us to an interesting strategy in art known as appropriation. And it’s appropriate to use here, because as we know, these systems are built on the works of other artists. But it’s maybe not so straightforward, and today I want to highlight some of the complex - perhaps even unanswerable - questions that surround the production and use of AI generated artwork through Diffusion.
Looking for Something Else to Do?
The following two videos offer different things. The first is a technical, but clear and accessible, explanation of how diffusion models work, in case anything above was unclear (or not technical enough!).
More to read:
Read: A Brief History of Diffusion, TechCrunch
Read: Anil Ananthaswamy (2023) The Physics Principle That Inspired Modern AI Art. Quanta Magazine